Here’s our definition of agentic testing :
“Agentic testing is testing performed by an AI agent that takes a natural-language goal, plans the test itself, runs it against your application, and verifies the outcome using multiple runtime signals. There's no hand-authored script underneath. The agent adapts to UI changes on its own.”
That is a tight definition. But a definition tells you what agentic testing is, not where it sits. In a real codebase, it shares a workflow with hand-written unit tests, AI-generated scripts, self-healing selectors, and manual passes. When thinking about implementing agentic testing, the obvious question that matters is where the line is. What counts as agentic testing? What's next to agentic testing? What resembles it but isn't? What does it overlap, and what does it leave alone?
To answer those questions, start thinking in sets .
The testing set
Agentic testing is a set. It sits inside a larger set, testing with AI, which sits inside the largest set of all, testing itself.
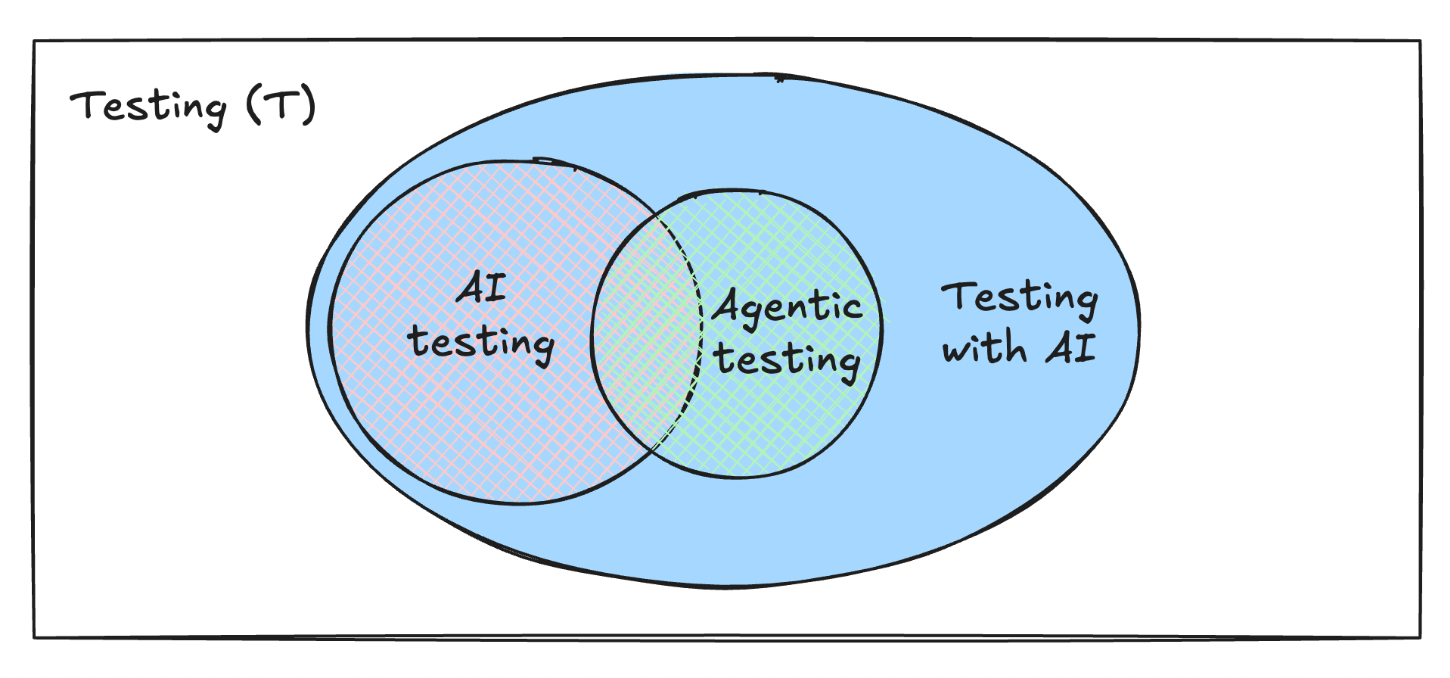
The universe is T, every test from the first line. Testing with AI, call it W, is the subset where AI contributes anywhere in the workflow: authoring, execution, observation, diagnosis, or maintenance. Everything in T outside W is tested with no AI in it; the deterministic, manual work that's still where most testing lives.
Inside W, AI-assisted testing (A) is human-authored test creation with AI's help. A person states the intent, usually in natural language, and AI turns it into the artifact: a test case, a Gherkin scenario, a Playwright script, an assertion, a checklist. The human owns the test. Once it exists, it runs like any other test.
Agentic testing, G, is testing that lives inside an agent loop. The human gives a goal, and the agent plans a path, acts on the app, observes what comes back through the DOM, accessibility tree, screenshots, network requests, console logs, and browser state , and adapts the path until it can reach or verify the goal. The agent owns the path. It can change a step, re-resolve a renamed button, or add an action the UI now demands, but it does not rewrite the goal to make the run pass.
A and G both sit inside W, and neither one contains the other.
A ⊂ W ⊂ T
G ⊂ W ⊂ T
A ∩ G is small, maybe emptyThe notation names three regions, but two sets crossing inside a third cut the space into five:
| Region | What it is |
|---|---|
| Outside testing with AI | no AI: hand-written, deterministic, manual |
| Inside the umbrella, outside both circles | AI assists: triage, test selection, judging, data, self-healing |
| AI-assisted only | a human authored the test with AI's help; it runs fixed |
| Agentic only | a human or a machine gives an intent, and an agent runs the whole loop |
| Both | one test mixes AI-authored fixed steps with an agentic step |
Three of those five are the ones worth most of your attention: AI-assisted only, agentic only, and the overlap where both are true. The rest of this takes the five regions in turn, starting with the two that are often confused with each other.
What's only AI-assisted testing?
A person owns the test, and AI helps write it, but once written, it runs as a fixed artifact. No loop, no runtime adaptation. This is where most AI in testing actually ships today.
- "Generate a Cypress test for this checkout user story," and you commit the result.
- Natural-language test cases generated from a feature description.
- Gherkin scenarios written from a requirements doc.
- LLM-generated Playwright or Selenium scripts you run unchanged.
- Assertions that an LLM writes for an API response you captured.
- Edge cases an LLM suggests from a product spec, once you turn them into tests.
- Acceptance criteria for an LLM converts into a regression suite.
- A flow you record by hand, which AI then converts into a maintained script.
The thing AI sped up here is writing the test, not living with it afterward. You get the script in seconds, but it's the same thing you'd have written by hand: a fixed list of selectors and assertions that does the same thing on every run. The model does its part once, and then you're left with a static file.
So it breaks the same way it always did. Selectors snap when the UI moves, assertions go stale, and the models writing your app are changing that UI all the time. You got the first draft faster and kept every bit of the maintenance. There's also a catch with the test itself: the model can write an assertion that's just wrong, one that passes for the wrong reason, so you still have to read what it wrote before you trust it.
What's only agentic testing?
The test runs inside an agent loop. You give an intent in plain language, and the agent works out the test itself, the steps, the selectors, any code it needs, then runs it against the app and adapts as it goes. Nothing gets saved as a script you maintain. The agent owns the whole path, and the intent it works from can come from a person or from a machine.
- "Verify a new user can sign up and reach the dashboard," and the agent plans the steps, drives the browser, and works out the checks itself.
- It decides pass or fail based on several signals at once: the DOM, the accessibility tree, a screenshot, the network calls, and the console, so it's checking behavior rather than whether one element exists.
- It hits a newly required field it didn't plan for and fills it instead of failing, or re-resolves a renamed button and caches the result so the next run skips the model.
- A coding agent launches a browser and verifies the UI change it just made.
- A CI agent reproduces a failing test, tries other paths, and proposes a fix.
- An agent crawls the critical flows from a sitemap, builds a repro from a production error, and checks it locally.
- A Momentic agentic step , where you state a goal and the agent plans, acts, observes, and adapts to reach it.
This is why agentic testing is its own category , not a kind of AI-assisted testing. Agentic testing isn't traditional automation, and it isn't codegen from natural language that you then maintain. The difference is the loop and the missing artifact. There's no saved script someone has to keep alive, so the breakage from a renamed class or a moved element mostly goes away. The agent re-resolves it and keeps going.
The one thing the agent can't touch is the goal. Say the goal is "user reaches the dashboard," and signup fails. If the agent quietly decides "signup form showed up" is good enough, it just moved the goalpost to pass itself. It can change the route, but the bar for success stays yours, which is why this kind of test needs a real oracle it checks against and can't edit, rather than an assertion it could quietly rewrite. Once a test can reach its goal more than one way, a single hardcoded assertion stops being enough.
You give something up for it. A fixed script is brittle but easy to read; an agent loop is sturdier but harder to pin down, and it costs you in speed and in runs that don't come out identical every time. You make the trade when the UI churns enough to keep breaking scripts, or when a coding agent needs to check its own work as it goes.
Self-healing doesn't reach this far. If a model only patches a broken locator within a script that otherwise runs correctly, the script is still calling the shots, and there's no real loop. That's assistance, and it sits in the margin.
Does anything land in both?
Most of what looks like both is just agentic. A person giving an intent and an agent running the loop is agentic testing, not a blend, because the person never authored a fixed test for the AI-assisted side to claim. To land in both, one test has to carry an AI-assisted authored part and an agentic part at the same time. That's narrow, and it may turn out to be empty, but a couple of things fit.
- A test that's mostly AI-generated, with deterministic steps and an agentic step or two dropped in where the flow won't pin down. The fixed steps came from AI-assisted authoring and run the same way every time; the agentic step runs the loop. One test, both circles.
- An AI-generated script handed to an agent as a starting plan, which the agent runs and adapts instead of executing line by line. The script came from AI-assisted authoring; the run is agentic. Though once the agent re-plans freely, it's fair to ask whether the script still matters or it's just agentic with a head start.
Outside cases like these, the two sets mostly sit next to each other rather than on top of one another.
Where does AI assist without authoring?
AI helps with testing, but it didn't write the test, and it isn't running it. A person authored the test, it runs the way it always did, and AI works around it.
- AI triages a failing run, clustering errors and proposing a root cause.
- AI classifies which failures are flaky and which are real.
- An ML model picks which tests to run for a given change, the test-impact-analysis case.
- AI clusters logs after a failure to pinpoint the cause.
- An LLM summarizes a CI run so a human can read it fast.
- AI generates synthetic test data for an otherwise static suite.
- An LLM-as-judge on outputs, scoring them against a rubric.
- AI flags visual anomalies in rendered output.
- Self-healing selectors patch a locator inside a scripted test.
What determines whether a test stays in this box rather than the AI-assisted circle is whether AI actually wrote the test. If it generated the data your hand-written assertion checks, that's help. If it wrote the assertion, that's authoring. LLM-as-judge is the one that trips people up: the model is acting as the judge of pass or fail, not writing the test and not driving it, so it stays here until you wire it into a loop.
None of the trade-offs from the other boxes show up here. The test still runs fixed and deterministic and easy to read, and AI just trims the work around it. For many teams, this is the safest place to introduce AI, and it's worth treating it as its own thing rather than a watered-down version of AI-assisted testing.
What is testing without AI at all?
No AI anywhere. A person wrote it, a person or a runner executes it, and it behaves the same way every time. OG testing.
- Human-written unit and integration tests.
- Hand-coded Selenium, Cypress, or Playwright scripts.
- Manual exploratory testing and manual test cases.
- Performance and load tests.
- Contract tests between services.
- Snapshot tests with no AI in the diff.
- Prompt regression tests a human wrote and a human judges, even though the system under test is AI.
It's easy to write this box off as the old way of doing things, but most of it should stay because it's deterministic. A hand-written unit test is fast, easy to read, and only goes red when something actually broke, which is what lets it block a merge with nobody watching. Property tests and fuzzers throw inputs at your code that you'd never think to list out by hand. None of this is waiting around to be replaced by an agent.
This box is also what everything else leans on. When an agent runs a loop, the thing it checks its work against is usually a plain deterministic assertion. So these tests stick around as testing gets adaptive, just in a new role, as the oracle the loop measures itself by. The real question is which tests have a good reason to leave, not how to empty the box. And it's a short list: end-to-end and integration flows over a UI that won't sit still, where keeping a fixed script alive finally costs more than the determinism is worth. Unit tests, perf tests, and property tests mostly have no reason to move.
How to place any test
Four questions settle almost everything.
- Is it producing evidence about expected behavior? If yes, it's in T.
- Is AI used anywhere in the testing work? If yes, it's in W.
- Is AI mainly helping a human author the test, or acting inside the execution loop? Authoring from intent goes in AI-assisted; a plan-run-observe-adapt loop goes in agentic; and both go in the overlap.
- Is the system under test itself AI? This one moves the test nowhere. It's a separate axis, and it's why a human-judged prompt eval lands outside W.
Two tiebreakers catch the rest. Self-healing that only patches a locator inside a fixed script is assistance, not an agent loop. And adaptivity alone doesn't make something agentic: fuzzing and exploratory testing change course at runtime without any agent making the calls, so they fall outside W.
The set your tests sit in, and where they're moving to
A definition tells you what agentic testing is. The sets tell you where it sits: inside testing with AI, beside AI-assisted testing, apart from the deterministic work that's still most of any suite. That's what the definition leaves out, and it's what lets you point at any test you own and name its set.
The sets aren't fixed, either. As agents churn your UI and write more of your code, tests shift out of the brittle fixed-script sets toward the agentic loop, while the deterministic base stays put. Knowing the sets is what makes that shift a decision rather than something flaky selectors force on you.