The promise was so beautiful. A team dedicated to your quality. Turnaround in hours, nay, minutes. 99.999recurring percent coverage. Outsourcing QA meant your team could focus on the product while the agency handled testing.
The reality was so different. Bug reports that arrived two days late, written by someone who'd never used the product. Slack threads longer than the code changes they were about. A coverage number that looked great on a dashboard and meant nothing in production. Outsourcing QA meant your team spent half its time explaining context to people who would forget it by the next sprint.
Outsourced QA doesn’t work. At this point, we’ve seen dozens of customers move from outsourced, agency QA to in-house testing, allowing them to own quality, ship with confidence, and move faster than they ever did with a vendor in the loop.
The hard part isn't making that call. The hard part is making the transition without shipping bugs during the gap. Here's how to make that transition without losing coverage along the way.
- Think in behaviors, not test scripts. Reset your framing from implementation-level scripts to behavioral statements about what your product must do.
- Audit what you have. Figure out what your vendor actually covers, because it's almost certainly less than the dashboard says.
- Define what “engineering-owned” means for your team. Align on the ownership model that fits your team size and structure.
- Run the new system in parallel before you cut the old one. Build confidence in the new system while the old one is still catching things.
- Migrate coverage, not tests. Write new behavioral tests from scratch instead of porting the vendor's scripts.
- Restructure your feedback loops. Compress the cycle from 72-hour bug reports to minutes-long CI checks.
- Measure the transition. Track DORA and operational metrics to prove the migration is working.
1. Think in behaviors, not test scripts
Before you start migrating anything, reset how you think about what you're migrating.
Outsourced QA trains you to think in scripts. Your vendor delivered a spreadsheet of test cases: click this button, type into this field, assert this element appears. That framing is implementation-level. It describes how to test, not what to test. When you start the migration, the instinct will be to recreate those scripts in a new tool. Resist. You're not porting a test suite, but defining what must be true about your product.
Start from what matters. Vendors cluster coverage around flows that are simple to script: login, password reset, basic CRUD, and static pages. Your test strategy should start from the other direction:
- What would cause a customer to churn?
- What would cause an incident at 3am?
- What would cause a deal to fall through during a live demo?
Behaviors come first. A test that verifies “a user can complete checkout with a promo code applied to a bundled subscription” matters more than ten tests that verify form validation on a settings page.
Thus, tests are behavioral statements. A well-written test describes the outcome your product must produce : “a user can log in,” “a workspace can be created,” “billing updates reflect in the dashboard.” When your UI changes, a behavioral test still holds. A script breaks.
Treat tests like product specifications. They are! They are a part of the specification of your product, just after the fact. When your team owns the tests, they stop being a checklist someone runs after development and become the contract that defines correctness. Writing them deserves the same strategic attention as writing a PRD. The migration is your opportunity to build that foundation correctly, not to carry forward the vendor's assumptions about what was worth testing.
2. Audit what you have
Before you cancel the vendor contract, figure out what your current setup actually covers. It's almost certainly less than the dashboard says.
- Map coverage to critical flows. Get a list of all the tests your vendor runs. Map each one to a real user flow in your product. You'll typically find that coverage clusters around easy-to-test flows (login, basic CRUD, static pages) and undercovers the flows that matter most: checkout, billing, permissions, integrations, and anything with conditional logic. The dashboard might say 80% coverage. The reality is that 40% of flows would actually cause a production incident if they broke.
- Evaluate test health. Pull pass/fail rates over the last 90 days. If more than 10% of tests are flaky, failing intermittently for reasons unrelated to real bugs, those tests are noise. They consume triage time without catching anything. Don't plan to migrate flaky tests. Plan to replace them.
- Check test freshness. When was each test last updated? If your product shipped a major feature three months ago and the test suite hasn't changed, the vendor isn't keeping up. Stale tests give false confidence, which is worse than no tests at all, because your team assumes coverage exists where it doesn't.
- Identify what's not tested. This is the most important finding. Ask your engineers one question: "What breaks in production that we never catch before it ships?" The answers tell you where your real coverage gaps are and where to focus first when you stand up the new system.
The goal of this audit is not to replicate the existing test suite. It's to understand which flows matter, which are actually covered, and which are theater.
3. Define what “engineering-owned” means for your team
“Engineering-owned tests” can mean different things depending on team size and structure. Before you start migrating, align on the model you're targeting.
Developer-written, developer-maintained
Every engineer writes and owns tests for the features they ship. This works best for teams under 15 where everyone has full-stack context and can reason about the product end-to-end.
The prerequisite is tooling. If writing a test requires learning Playwright selectors, debugging flaky waits, and configuring browser environments, developers won't do it. The testing tool has to be low-friction enough that writing a test feels like writing a PR description rather than a side project. Natural language test authoring makes this viable in a way that code-based frameworks never did: an engineer who just built a billing feature can write "verify that upgrading from free to pro updates the invoice immediately" and have a working test in minutes.
The risk is coverage gaps. No single engineer sees the whole product, so cross-feature interactions fall through the cracks. Mitigate this with:
- A shared test health dashboard visible to the whole team
- A recurring (brief, async) review of coverage gaps by a tech lead
- Clear ownership of integration-level tests that span multiple features
This model works even for non-engineering teams when the tooling is right. At Quora , the Product Operations team, not engineers, automated 500+ manual test cases for Poe.com using natural language tests, cutting daily test execution from 7 hours to 30 minutes.
Embedded QA engineer(s)
One or two QA-focused engineers own test strategy, write the complex tests, and review the overall coverage map. Developers write basic smoke tests for their own features. This works well at 15 to 50 engineers, where the product surface area is too large for any single developer to hold in their head.
The key difference from outsourcing: these QA engineers sit in your standups, absorb product context, and accumulate institutional knowledge about failure modes. After six months, an embedded QA engineer knows that:
- The discount code logic breaks when combined with annual billing
- The search index takes 30 seconds to update after a bulk import
- The mobile web checkout has a race condition on slow connections
An outsourced vendor never builds this knowledge.
The role itself is evolving. Embedded QA engineers increasingly spend less time executing tests and more time defining test strategy, writing behavioral specifications, and architecting coverage. Think of the role as a test architect who ensures the right things are tested, while the tooling handles execution and maintenance.
Platform team with product team ownership
At scale (50+ engineers), a small platform or quality team manages the testing infrastructure: CI/CD integration, test environments, parallel execution, test health metrics, and tooling standards. Product teams own coverage for their own features. The platform team doesn't write product tests. They make it easy for everyone else to.
This model works because it separates two distinct problems:
| Product teams | Platform team | |
|---|---|---|
| Strength | Domain knowledge of what needs testing | Infrastructure expertise to make testing fast and reliable |
| Owns | Test definitions, coverage for their features | CI/CD integration, execution environments, and tooling standards |
| Success metric | Critical flows are covered, and tests are meaningful | Product teams write and run tests without filing infra tickets |
When these responsibilities are merged into one team, both suffer. Product coverage stalls because the infra work is urgent, or infrastructure degrades because product tests are the priority.
None of these models involves handing tests to an external team. All of them keep quality decisions inside the org. And all three are moving in the same direction: engineers owning quality directly, with dedicated QA roles evolving from manual test execution toward test strategy, coverage architecture, and behavioral specification. The traditional QA engineer who clicks through flows and writes bug reports is being replaced by the test architect who defines what must be true about the product and ensures the system verifies it continuously.
Be explicit about which model you're targeting today, but design for where your team is heading. It changes how you staff the transition, how you onboard the tool, and what success looks like in three months.
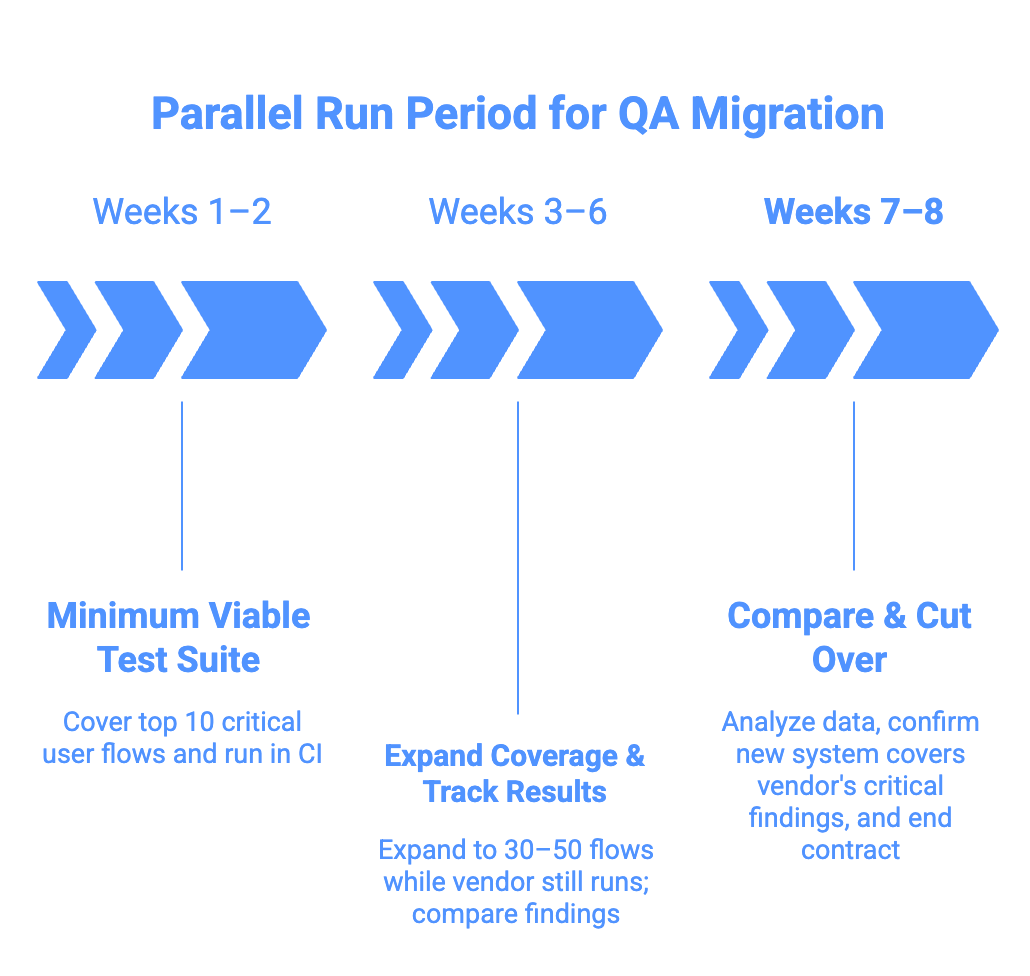
4. Run the new system in parallel before you cut the old one
This is where most migrations go wrong. Teams cancel the QA vendor, then scramble to build coverage from scratch. There's a gap. Bugs ship. Confidence drops. Engineers lose trust in the new approach before it has a chance to prove itself.
Instead, run both systems simultaneously for 6 to 8 weeks. Yes, it costs. But it will allow you to understand your new workflow while still leaning on theirs.
- Weeks 1–2: Cover your top 10 critical flows. Pick the 10 user flows that would cause the most damage if they broke in production. Signup, checkout, core workflow, billing, permissions, the flows where a bug means revenue loss or customer churn. Write tests for these first. Run them in CI on every PR. This is your minimum viable test suite.
- Weeks 3–6: Expand to 30–50 flows while the vendor still runs. You're building confidence in the new system while the old one still catches things. Track what each system catches during this window. You'll likely find two things: the new system catches issues faster (because it runs in CI rather than on a 24-hour cycle), and the vendor catches fewer unique issues than you expected. Most of what the vendor reports will already be flagged by the new system, often hours earlier.
Weeks 7–8: Compare results and cut over. By now, you have data. What the new system catches, what the vendor catches, and where the overlap is. If the new system covers the vendor's critical findings and catches them faster, you can confidently end the contract. If there are gaps, you know exactly where they are and can close them before pulling the trigger.
Retool followed a similar pattern. Their engineering team ran a 15-page manual QA checklist before every release, alongside a Cypress suite that couldn't handle the complexity of their product. After standing up Momentic tests in parallel, they retired the checklist entirely and went from biweekly releases to four times a week.
The parallel period costs money, but it costs far less than a production incident caused by a coverage gap during the transition (and that makes you scramble back to the vendor).
5. Migrate coverage, not tests
Don't try to recreate your vendor's test suite line by line. Their tests were written for their workflow, their tooling, and their understanding of your product, which was probably shallow.
Instead, migrate by flow:
- List every critical user flow in priority order (from the audit).
- For each flow, write a new test from scratch in the new tool.
- Validate that the new test catches the same class of issues as the old test.
- Move to the next flow.
This is faster than translating old tests and produces better results. A test written by someone who understands your product, describing behaviors rather than clicking through scripts, will be more reliable than a ported test carrying assumptions and debt from the old system. This is the moment to apply the framing from your test strategy: write each new test as a behavioral statement about what your product must do , not as a reimplementation of the vendor's procedural script.
For teams with large existing Playwright or Selenium suites, whether homegrown or vendor-managed, the same principle applies. Don't try to make old scripts work in a new context. The maintenance burden you've accumulated in those scripts is the problem you're solving. Porting the scripts ports the burden with them.
Start fresh. Write tests that reflect how your product works today, not how it worked when someone wrote the original test six months ago.
6. Restructure your feedback loops
With outsourced QA, the feedback loop looked like this: build the feature, hand it to the vendor, wait for their cycle, read the bug report, context switch back to the code, try to reproduce, fix it. That loop takes 24 to 72 hours on a good week.
With engineering-owned tests, the loop compresses to: build the feature, run tests automatically on the PR, see results in minutes, and fix before merge.
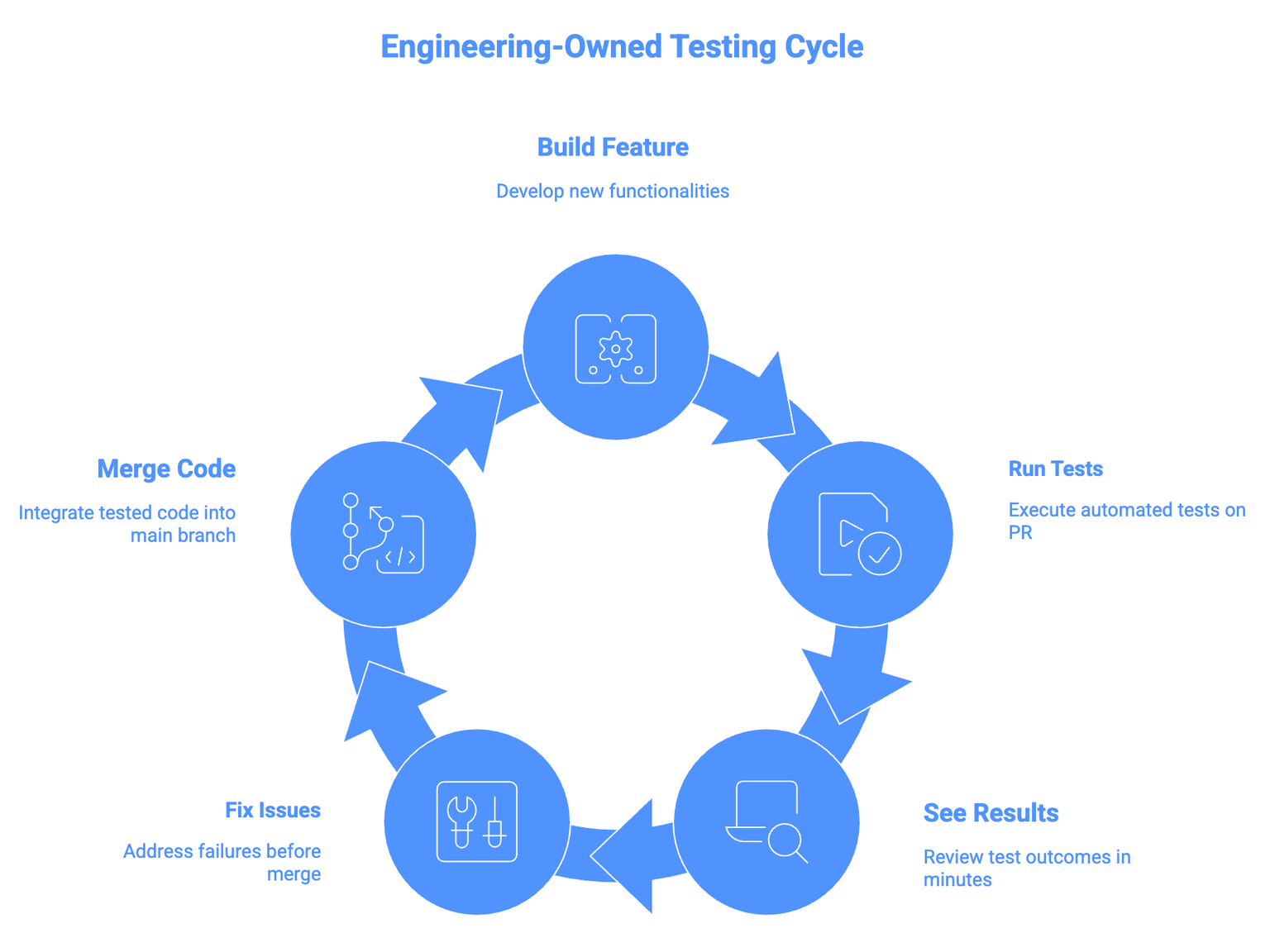
Making that compression real requires a few concrete changes:
- Tests run on every PR. This is non-negotiable. If tests only run nightly or on a schedule, you've recreated the outsourced model with different tooling. The value is in immediate feedback on the code that's about to merge.
- Results show up where engineers already work. GitHub check, Slack notification, and IDE integration. Not a separate dashboard that nobody checks until deploy day. The information should be impossible to miss without adding a new tab to anyone's workflow.
- Critical failures block merge. For your top 10-20 flows, a test failure should prevent the PR from being merged. This is the quality gate that replaces the vendor's bug report. It's faster, more reliable, and doesn't require a meeting to interpret.
- Non-critical failures are visible but non-blocking. For lower-priority flows, surface failures as warnings. Engineers can assess whether the failure is relevant to their change or a pre-existing issue.
- Cancel the QA sync meeting. If you had a recurring meeting to coordinate with the vendor (what's in scope, what's blocking, what's the status of that bug report from Tuesday), cancel it. The information the meeting provided now comes directly from the CI pipeline.
One thing teams notice after making this transition: engineers start testing earlier in the development process, not because of a mandate, but because the feedback is fast enough to be useful while they're still working on the feature. When writing and running a test takes minutes instead of days, testing stops being a phase at the end and becomes something that happens continuously. Quality moves earlier in the development cycle as a natural consequence of the tighter loop .
7. Measure the transition
Deployment frequency and change failure rate are DORA metrics that are well benchmarked and directly affected by a QA migration. The others are operational metrics specific to the transition. You won't find industry benchmarks for them, but you should baseline them before the migration starts so you can track the delta.
DORA metrics:
| Metric | Before (outsourced) | Target (engineering-owned) |
|---|---|---|
| Deploy frequency | Weekly or biweekly | Daily or per-PR |
| Change failure rate (production incidents per release) | Baseline before migration | Track reduction over 3–6 months |
Operational metrics to baseline:
| Metric | Before (outsourced) | Target (engineering-owned) |
|---|---|---|
| Time from bug introduced to detection | Typically 24–72 hours | <1 hour (caught in CI) |
| Time from detection to when the engineer sees it | Typically 2–8 hours (report, triage, Slack thread) | < 5 minutes (PR check) |
| Engineering hours/week on QA coordination | Varies, but often 10–25 hours across the team | 0 (no sync meetings, no clarification threads) |
| Test maintenance hours/week | Vendor manages (you pay via coordination overhead) | Near-zero with self-healing tools; 1–2 hrs/week without |
Don't expect all of these to improve in week one. The operational metrics, time to detection, and time to engineer, improve immediately. The DORA metrics improve over one to three months as coverage builds and engineers start trusting the new system enough to ship more frequently.
If you're not seeing improvement in the operational metrics within the first two weeks, something is wrong with the setup, not the approach. Check that tests are actually running on every PR, that results are visible in the right places, and that the critical-flow tests are stable enough to be meaningful signals.
The transition is the easy part
The mechanical steps of moving from outsourced QA to engineering-owned tests are straightforward: audit, build in parallel, cut over. The harder shift is cultural.
This migration is the moment leadership signals that quality is a first-class engineering value, not a line item on a vendor invoice. Your engineers need to believe that quality is their responsibility, that the tests are trustworthy, and that the tooling won't become another maintenance burden they resent.
The audit builds conviction that the old system wasn't doing what everyone assumed. The parallel period builds evidence that the new system works. The faster the feedback loop, the stronger the habit. And the behavioral test suite you build along the way becomes something the vendor never gave you: a durable, team-owned specification for how your product is supposed to work.
Give each of those stages enough time to do its job, and the rest follows.