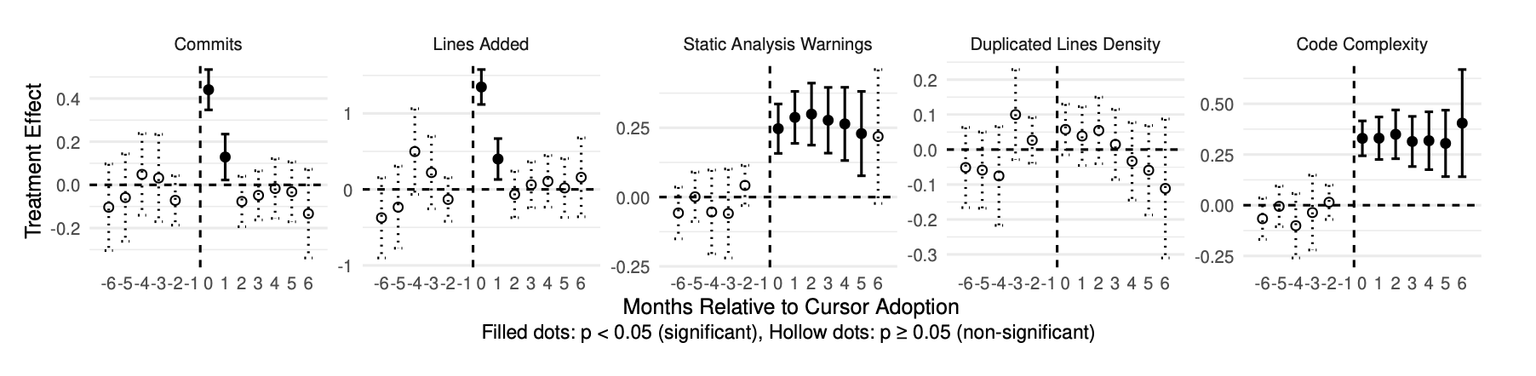
“We find that the adoption of Cursor leads to a statistically significant, large, but transient increase in project-level development velocity, along with a substantial and persistent increase in static analysis warnings and code complexity.”
That’s the finding of a CMU study that tracked 806 GitHub repositories that adopted Cursor, compared with 1,380 matched controls. The velocity is real, briefly. The quality isn’t, consistently.
But we all know this isn’t going to stop teams from using AI. So, the question is: how do we keep the velocity and quality high when using tools like Cursor, Claude, and Codex?
Velocity up, quality down, and a ton of vibe-debt
Most AI productivity claims come from surveys (i.e., vibes) or lab experiments. The CMUers used a difference-in-differences design , matching Cursor-adopting repos against similar non-adopting repos based on six months of pre-adoption data. The closest thing to a controlled experiment you can run at this scale.
The highlights:
- The velocity spike is huge and temporary. Lines added jumped 281% in month one, 48% in month two, and back to baseline by month three. This isn't the modest 6-20% sustained improvement that earlier Copilot studies found. It's a burst that fades.
- The quality decline is smaller and permanent. Static analysis warnings up 30%, code complexity up 42%, both still elevated six months later. The velocity came and went. The debt moved in.
- The debt actively kills the velocity. A ~3x increase in code complexity or ~5x increase in static analysis warnings fully cancels the velocity benefit. The debt compounds.
- AI-generated code is inherently more complex. Even after controlling for “more code = more complexity” (trivially true), Cursor adoption produced a 9% baseline complexity increase. The code itself is harder to understand, not just more plentiful.
- Sustained tool investment matters. Repos where developers actively refined their .cursorrules kept velocity gains longer. Repos that just turned Cursor on followed the boom-bust curve. Configuration isn't optional.
- Heavy usage makes quality worse, not better. Robustness checks showed that high-confidence, intensive Cursor usage amplified the quality effects. The signal gets stronger the more you use it.
The warning breakdown is worth a look, too. The categories that spiked hardest were:
- Naming conventions (+21/repo/month)
- Code hygiene (+16)
- Code complexity (+15)
- Code style (+15)
All contextual violations: valid code that doesn't match how the project does things. Meanwhile, API usage and concurrency warnings actually decreased, suggesting LLMs do improve some patterns.
AI has scaled code overnight, but not verification
In traditional development, this mismatch is manageable. Teams write code at human speed and review it at human speed. The two roughly keep pace. But look at the numbers from the CMU study: With AI-assisted development, production velocity jumped nearly 4x in a single month while quality verification infrastructure stayed exactly where it was.
This is a scaling gap, and one that compounds. Every month you produce faster than you verify, you accumulate debt that makes next month's verification harder. The GMM models put a number on the tipping point: ~3x increase in complexity or ~5x increase in warnings, and the velocity benefit is gone entirely. You're not just back to where you started. You're behind, with a harder codebase.
A natural response to a QA scaling gap is to throw people at it. More reviewers. More manual testing. But the scaling doesn’t work. You are bringing a linear scaling to an exponential fight.
The warning distribution explains why this doesn't work. The categories growing fastest–naming conventions, code hygiene, code complexity–are all contextual. They're violations of how this particular project does things, not violations of universal programming rules. A reviewer who doesn't carry deep codebase context will catch the easy stuff (unused imports, obvious type errors) and miss the contextual stuff, which is exactly what's growing fastest.
What actually scales
Here's what's interesting about those warning categories. The CMU paper measured structural quality in terms of naming, complexity, and style. It didn't measure behavioral correctness at all. It can't tell you whether the login flow still works, whether the checkout completes, or whether the API returns the right data after 281% more code landed in a month.
The structural stuff is the easy layer to catch. The behavioral drift underneath is what actually breaks things for users.
This is why we talk about truth-driven development . When code changes faster than anyone can inspect it, you need a stable definition of correctness that doesn't depend on reading every diff. Behavioral tests that define what must be true:
- “A user can log in.”
- “Billing updates reflect in the dashboard.”
- “A logged-out user can't reach /billing.”
Not line coverage (you can have 90% and still ship broken flows). Not code review (you can't review at 3x the usual rate). The implementation can change constantly. The truth stays fixed. That's what scales with AI velocity, because it doesn't care who or what wrote the code. It cares whether the system does the right thing.
The question has shifted from "can we build it?" to "can we trust it?" AI answered the first question. Nobody has answered the second one at the velocity AI now demands.
This is a gap in this research. The paper recommends scaling test coverage with lines of code added, which is correct. But it frames testing as something that happens after code lands, a verification step at the end of the pipeline. When code lands at 281% of the usual rate, downstream verification will always be behind. Testing has to move from a phase you pass through to infrastructure that runs continuously, at the same cadence as code generation.
In practice, that looks like:
- Every PR generated by Cursor or Claude gets tested against behavioral truths before it merges. Not “does this function return the right type,” but “does the user journey still work end to end.”
- Tests that define the specification , not just verify it.
- Tests that self-heal when the DOM shifts, so your team isn't spending 40% of their sprint maintaining brittle selectors while the AI generates another thousand lines.
The CMU paper found that repos actively refining their .cursorrules kept velocity gains longer. The same logic applies to testing: teams that invest in their testing infrastructure, not just their code generation tools, are the ones that sustain the speed. AI should test the code it writes. That's the only way the math works.
The window
The CMU data shows velocity gains concentrate in the first one to two months. After that, debt dynamics take over. The window to get testing infrastructure in place is before you adopt AI coding tools, or, at worst, at the same time.
Teams adopting AI coding tools without a plan for how verification scales with production are running the exact experiment this paper measured. The results are in: a transient spike, a permanent quality decline, and a codebase that's harder to work with than the one you started from.
The velocity is real. The 281% spike is real. And the debt that eats it is real, too. The teams that keep the speed will be the ones that defined their truths before they turned on the AI. Everyone else is just generating technical debt faster.