This is the first part of our guide on agentic testing, covering what agentic testing is, what it isn't, and why teams need to start understanding it now. You can check out the second part to understand how agentic testing works here: https://momentic.ai/blog/how-agentic-testing-works .
Agentic testing is software testing performed by AI agents that plan, run, observe, and adapt tests on their own. The testing agent uses multiple signals, such as DOM, accessibility tree, screenshots, network requests, and console logs, to decide whether an application behaves correctly. There's no hand-written script and no fragile selector chain. You specify a goal in natural language, and the agent figures out how to verify the application against that goal.
That's the short version. The longer version requires unpacking the four-verb loop the agent runs, the bundle of signals it uses to make decisions, and why the new category has popped into existence at all. This guide covers each of those, along with how agentic testing actually works under the hood and who in an engineering org tends to own it.
What is agentic testing?
Agentic testing is testing performed by an AI agent that takes a natural-language goal, plans the test itself, runs it against your application, and verifies the outcome using multiple runtime signals. There's no hand-authored script underneath. The agent adapts to UI changes on its own.
The cleanest way to read that definition is to take its constituent parts seriously. Each verb in "plan, run, observe, adapt" maps to a specific piece of the agent's runtime, and the multi-signal observation surface is what separates an agentic test from a glorified Playwright script.
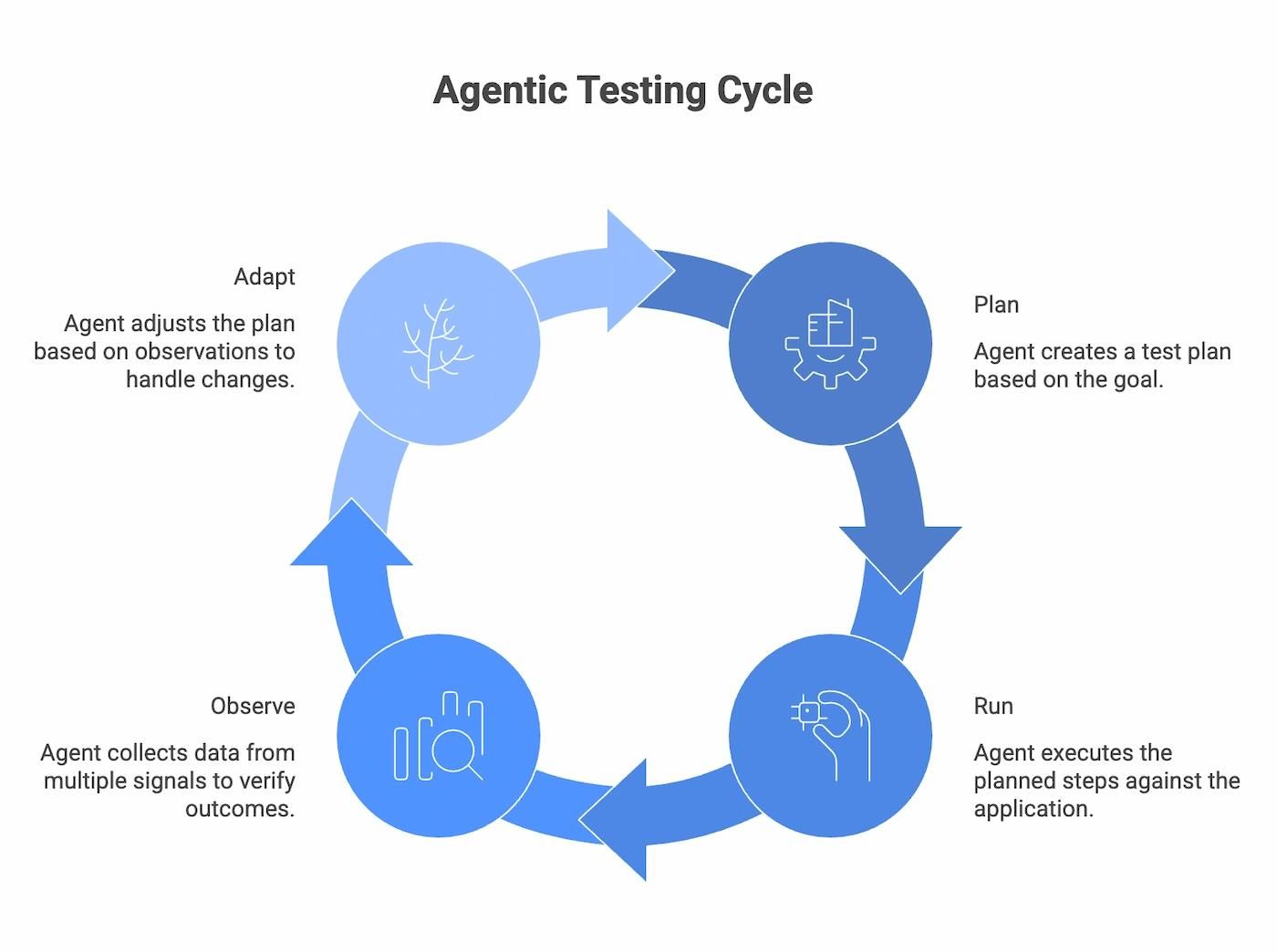
1. Plan
Given a goal like "verify that a new user can sign up and reach the dashboard," the agent first plans, decomposing the goal into a sequence of steps:
- Navigate to the signup page
- Fill in an email and a password
- Submit
- Verify the dashboard loads in a logged-in state.
The agent needs to produce a chain of thought, name the tools it will use, and order them before executing anything. The plan is a draft, not a script. As the agent runs each step, it can revise the plan locally if the page doesn't match what it expected.
2. Run
Each step in the plan gets executed against the running application. When the agent reaches "fill in the email field," it identifies the email input on the live page, types the value, and moves on. The author of the test never specifies which element the agent should click or type into. The agent figures out the target from the page itself, in the moment.
3. Observe
After every action, the agent reads the page state through several signals. After clicking the signup submit button, it might check that the URL changed to a dashboard route, that the page heading reads "Welcome," that the network shows a successful signup call, and that the browser console is clean.
No single signal decides the outcome. The agent reasons over the bundle.
4. Adapt
When the page doesn't match what the agent expected, it re-reads, considers why, and tries an alternative path instead of failing. If the signup form includes a "Full name" field the agent didn't plan for, it doesn't throw an error. It notices the missing required input, determines it's needed to proceed, fills it in, and resubmits. The same loop kicks in when a button has been renamed, an element has moved, or a request is slower than usual.
The signals an agent reads
A modern agentic test isn't just about reading the DOM. It fuses several runtime signals to decide whether the application is behaving correctly.
| Signal | What it is | Why agents use it |
|---|---|---|
| DOM | Raw HTML tree | Baseline element discovery, attribute checks |
| Accessibility tree | Semantic role/name/state representation of the page | Stable across CSS changes, resistant to minified class names, the dominant agent input today |
| Screenshots | Pixel-level page snapshot | Catches visual regressions, handles custom canvas-rendered UIs like charts, maps, and design tools |
| Network requests | XHR and fetch traffic | Verifies the right API was called with the right payload |
| Console logs | JavaScript errors and warnings | Surfaces uncaught exceptions, the UI might silently swallow |
| Browser state | Cookies, storage | Verifies auth and persistence |
The combined surface is what makes agentic tests verify behavior rather than DOM structure. A scripted test asserts that a particular element with a particular class is visible. An agentic test can verify that the success toast appeared, that the network call returned 200, that the console is clean, and that the resulting dashboard shows the correct user name, all from a single intent.
What agentic testing is not
The category has enough adjacent ideas around it that the boundaries are worth drawing explicitly.
- Agentic testing is not traditional test automation. Traditional automation (Selenium, Cypress, vanilla Playwright) executes hand-written scripts against pinned selectors. The script is the contract; agents don't author scripts.
- Agentic testing is not AI-assisted authoring. Tools that have an LLM generate Playwright or Cypress code from natural language are still producing scripts that humans maintain, debug, and patch when selectors break.
- Agentic testing is not self-healing selectors. AI that patches broken locators inside scripted tests is repairing the script. The script still defines every step.
- Agentic testing is not visual regression testing. Pixel diffs between runs are one signal an agent might use. They give you a single channel of verification, not a full paradigm on their own.
- Agentic testing is not an LLM-as-test-generator. Having an LLM write a script that then runs deterministically is generative authoring with extra steps. The execution layer is still scripted, with all the brittleness that implies.
Agentic testing is a generational shift. We’ve gone from scripted automation (Selenium, Cypress, vanilla Playwright) to AI-assisted scripting (self-healing locators, codegen from natural language) to agentic testing.
Why agentic testing now?
Two forces are pushing this category from "interesting" to "necessary": the volume of AI-generated code now flowing through engineering organizations, and the verification gap that volume creates.
Coding agents are in the production path
Even before the great Claude-code rush of early 2026, AI was already in the production path for most teams:
| Metric | Value | Source |
|---|---|---|
| Developers using AI tools at work | 79% | Stack Overflow |
| GitHub Copilot users | 20M+ | GitHub |
| Share of code AI-generated for active Copilot users | 46% (up from 27% at launch) | Microsoft |
| Highest AI-generated share by language (Java) | 61% | Microsoft |
Now, agents are the growth space. The 2026 JetBrains AI Pulse survey showed that “22% of developers already use AI coding agents” and 66% of teams plan to within 2026.
For testing, the volume of AI-generated code matters less than the rate of UI change it entails. When agents are renaming components, restructuring props, and refactoring CSS classes dozens of times per week, the churn rate in any non-trivial frontend is an order of magnitude higher than what scripted test suites were designed for.
Selector-based automation can't keep up
The flakiness data has tracked the change directly:
| Source | Finding |
|---|---|
| Bitrise Mobile Insights 2025 (10M+ builds) | Test flakiness affected 10% of teams in 2022 and 26% in 2025, a 160% increase in three years. |
| An Empirical Analysis of Flaky Tests | Flaky tests account for 4.56% of all test failures at Google and cost the company over 2% of coding time. |
| Systemic Flakiness | Developers spend up to 1.28% of their time repairing flaky tests; 56% see flaky tests monthly, weekly, or daily. |
True flakiness, in the non-determinism sense, accounts for only some of the maintenance pain. Most of it is deterministic breakage from UI churn. A test breaks the moment a developer renames a CSS class, adds a wrapper div, or restructures a component. When the developer making those changes is an AI agent moving ten times faster than a human team, the selector tax compounds.
The downstream effect on teams is well-documented. Developers who encounter flaky tests are significantly less likely to investigate subsequent test failures. The whole suite starts to function as background noise. That's the trust-decay loop scripted automation can't escape at AI-coding velocities.
Verification has to live inside the agent loop
There's a deeper reason agentic testing matters now: AI coding agents need fast, reliable verification to function well, and they need it inside their own working loop. Without it, they confabulate.
The reliance on verification goes deeper than workflow advice. It's how these models learned to code at all. Frontier reasoning models are trained with reinforcement learning on verifiable rewards: the model generates a candidate solution, a compiler runs it against a suite of test cases, and the correct ones get rewarded. DeepSeek's R1 training worked exactly this way for code. Tests are signal, and agentic testing puts that same signal back into the loop at runtime.
The Stack Overflow frustration data shows the same thing from the developer's side:
- 66% say their biggest frustration with AI tools is "solutions that are almost right, but not quite."
- 75% don't trust AI answers without verification.
Harness's 2026 State of Engineering Excellence report puts a cost on it: developers estimate roughly 31% of their day now goes to AI-related work that shows up in no metric, much of it reviewing AI code and fixing its defects, and 81% of engineering leaders say code review time has risen since they deployed AI.
Putting those together, the structural argument is clean. AI-generated code without fast verification is “almost right, but not quite” code. Closing that gap requires verification that is itself agentic, because the rate at which the application surface changes has outrun the rate at which humans can author and maintain scripts. Agentic testing is the verification layer for an AI-coding-agent-driven SDLC.
Now read how agentic testing works works in practice, and best practices for implementing inside your organization: https://momentic.ai/blog/how-agentic-testing-works