Part 1 of our series on teaching browser agents to understand user intent at scale: how we scaled from 80k to 1B caches, serving 1M queries per day, while migrating from Postgres to ClickHouse
Caching has always been key to keeping Momentic more cost-effective, fast, and reliable.
As an end-to-end quality and testing platform, the two key metrics that build customer trust are a) how quickly we can identify when things break, and b) how consistently we deliver the same results given the same inputs. Both come down to the same underlying problem: teaching the agent to understand and remember what the user actually meant.
Speed. Fast feedback keeps the development loop tight: PR checks finish quickly, and engineers can keep merging code.
Accuracy. Consistency protects trust: if tests are always passing locally but flaking in CI, eventually the entire suite gets ignored.
Using AI allows Momentic to intelligently adapt to customers’ product changes, reducing false positives (unnecessary failures). Fewer failures mean engineers spend less time context switching and product ships faster.
However, AI is also expensive to run, and doesn’t always behave the same way. If we were to rely only on AI, it would be incredibly costly to run, each step would take several seconds to execute, and sometimes it would hallucinate clicking the wrong button.
How Momentic generates and resolves caches
In Momentic, any step that interacts with an element (think click, hover, or even element checks) can be cached.
After using AI to locate an element based on the user’s intent, Momentic generates a list of unique, matching CSS selectors for that element. We also snapshot the DOM node.

During subsequent runs, we evaluate all the selectors against the current page state and group them by matched element. The element with the most matching selectors is evaluated against the previous snapshot to determine if it’s similar enough to the original to be reused.

Problems with cache accuracy as Momentic scaled
As Momentic scaled to millions of daily runs on its platform, across 1000+ engineer organizations, we started to encounter a couple of common failure modes.
Failure mode 1. Cache pollution across branches
Different branches contained various minor product changes which might cause a cache that resolves on one branch to not work on a different branch. Since all branches shared a single cache, it was common for elements to get stuck in loops of cache busting, where one branch would regenerate a selector that worked with it’s changes, but didn’t work with another’s, causing the other to in turn regenerate the cache.
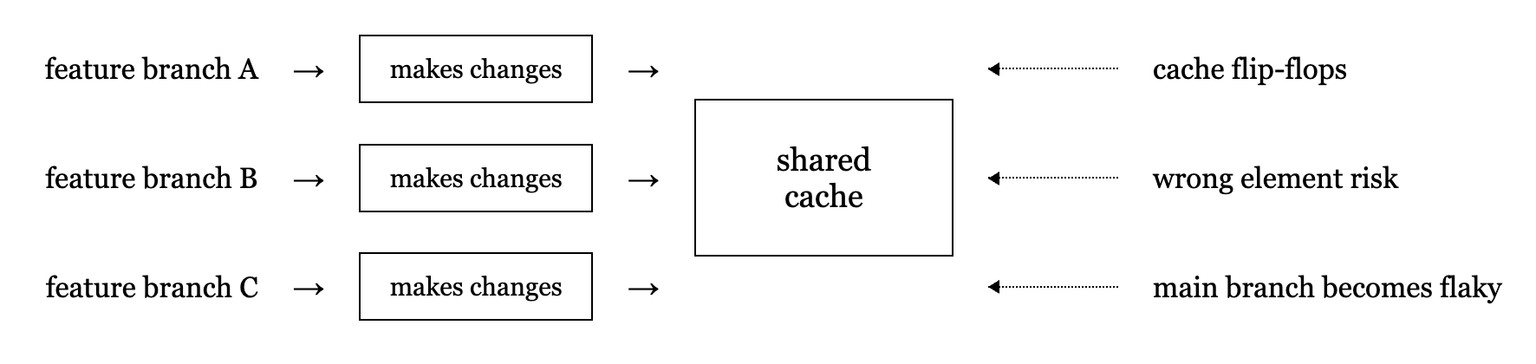
This was impacting users because it led to tests touching product areas where many engineers were making changes running slowly because they were almost never cached.
It also drove up our own costs because every time the cache busted, we had to pay for an AI completion.
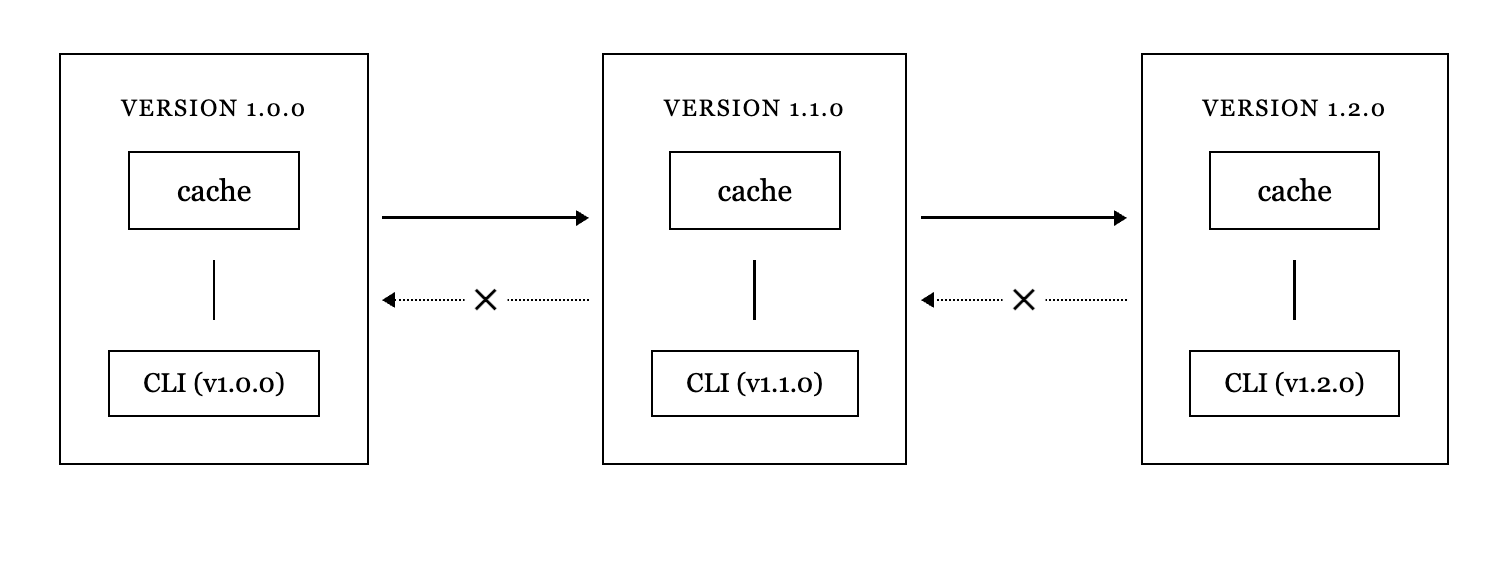
Failure mode 2. Cache pollution across Momentic versions
Newer Momentic versions generated caches optimized for the latest release. If a repository contained branches with different versions, the newer ones corrupted caches for older ones.
When customers changed Momentic versions, branches still using the older version would often see very low cache hit rates because the older CLI couldn’t use caches generated by the newer one. This meant that every upgrade led to a period of slower execution and higher costs until everyone on the team rebased onto the main branch.
Failure mode 3. False cache misses (validation too strict)
Because of the way we compared snapshots of DOM nodes, it was very common to bust the cache over inconsequential changes. It’s common for sites to have randomized classnames, IDs, or hrefs. When these changed, it often caused the cache to bust despite the element itself still appearing the same to the user.
Minor styling changes or even className randomization across releases caused unnecessary cache busting and slowness.

Failure mode 4. False cache hits (validation too loose)
For short elements without many attributes, often in lists and tables, it was common for our validation to miss the features that mattered to the user’s intent. For example, the user might say “the menu button in the Alice row.”
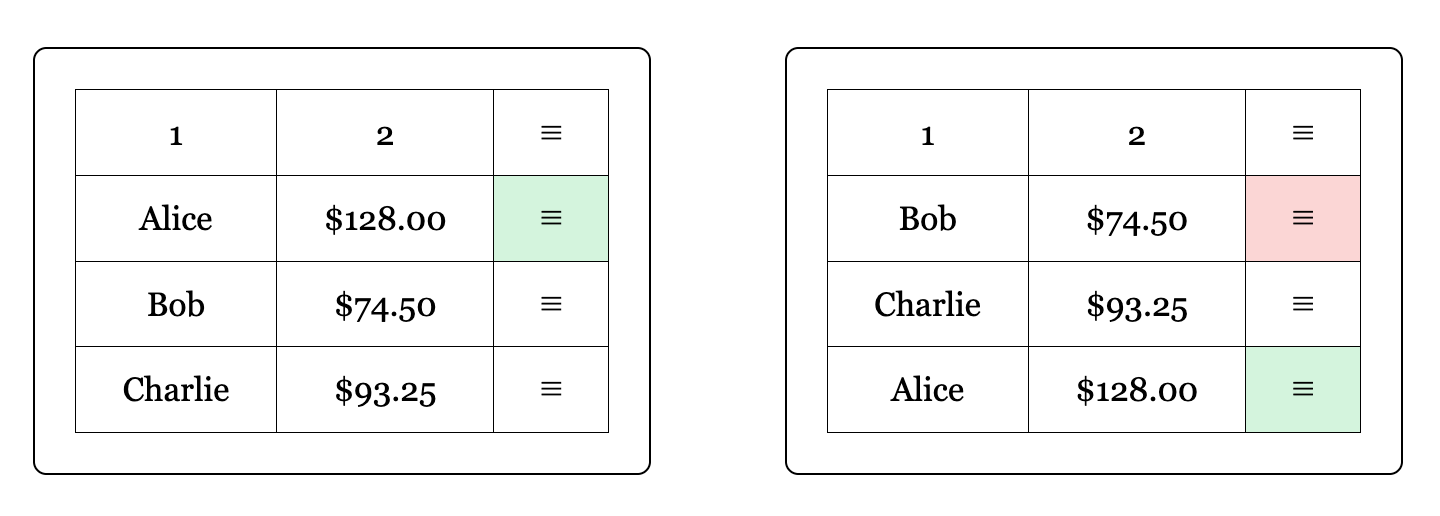
In this situation, the majority of the selectors would often be nth child based, causing them to select the wrong element if the ordering of the rows changed in later runs. This is especially hard to debug for users who aren’t very familiar with how Momentic works.
This would lead to either incorrectly passing tests, or tests failing later on inexplicably. For example, if I accidentally decided to open the menu for Bob, I might not realize until ten steps later when checking that Bob is in my team that I actually edited the wrong user.
How we stopped cross-branch cache pollution
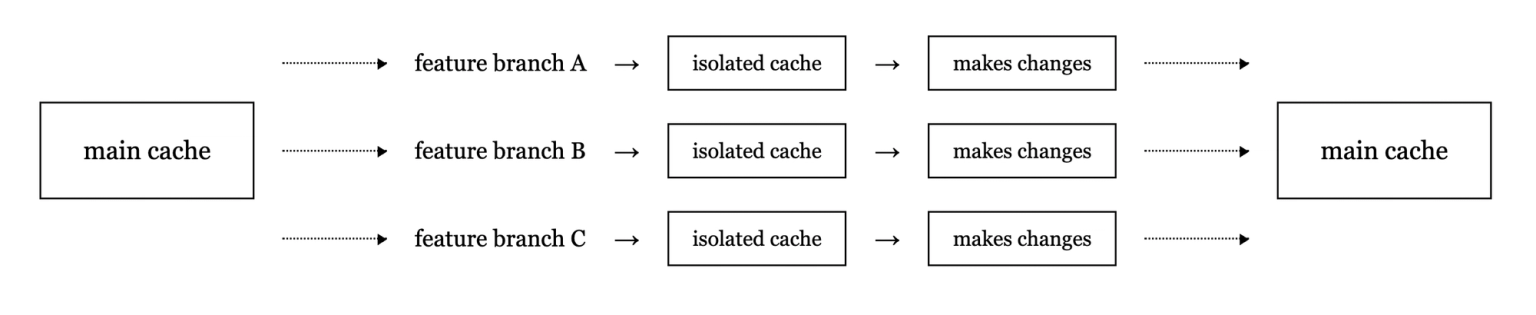
In order to prevent interference across branches and versions, we had to isolate their caches.
We started by storing a different cache for each branch/version combination.
This made the caches fully isolated, but still had a few limitations:
- When you create a new branch, there’s no cache, so inevitably, the first test runs on that branch are slow and unpredictable.
- Conversely, when a pull request gets merged back into main, the cache changes from that branch are forgotten, leading to unpredictable behavior when testing changes that were made on the branch. We observed several instances where tests would pass on a feature branch but fail on main due to AI consistency issues.
- Similarly, when you change Momentic versions, results are slow and unpredictable because the cache is reset.
In order to solve the branching problems, we had to allow branches to inherit caches from other branches. We did this by tracking when they were created, and seeding their caches with the latest values from the merge base commit on main. We ensured continuity on main by checking if a commit was created by merging a branch, and if it was, also pulling in the latest caches from that branch to make sure that we had the complete picture.
We also enforced that as new versions of our CLI were released, they could only use caches generated by versions less than or equal to their own version. This prevented them from attempting to use caches that were incompatible. We did this by filtering out caches that had a version greater than the current CLI version during resolution.
How we taught the cache to respect user intent
When caches were created, there was nothing explicitly verifying that the resolved element matched the user’s original intent. This was particularly challenging because the validation rules need to change depending on the user’s prompt.
To illustrate this issue, consider the following scenario:

If the user’s prompt was “the add to cart button,” the cache can be used in both cases, but if the user’s prompt was “the blue button,” the cache must be busted.
Our similarity check was a best-effort attempt at a generic criteria, but it was far from perfect. In order to solve this problem, we needed to generate some conditions to dynamically verify that we remained consistent with the original query. We landed on two types of conditions which can be used to validate the element:
- Attributes are properties of the element itself that must remain the same in order for the element to match the user’s query. These could include text, color, or any arbitrary HTML attribute. For example, the user might ask for “The large profile image in the middle of the page.” In this case, the element must be an image, be large, and be located in the middle of the page. Depending on the user’s site, it might also need to have alt text like “profile image.”
- Related elements are other elements on the page that the user used to identify their target. Related elements can themselves have required attributes. For instance, the user could say “the login button above the sign up button.” In this case, there’s one related element: the sign up button, which must say “sign up” and be below the main element.
In order to generate these, we modified our element locator agent to classify which attributes it used in its reasoning to identify the element. We also had it generate targets for all of the additional elements that it considered. In our experimentation, we found the best results when these classifications were the last thing generated, after the reasoning and the target element itself.
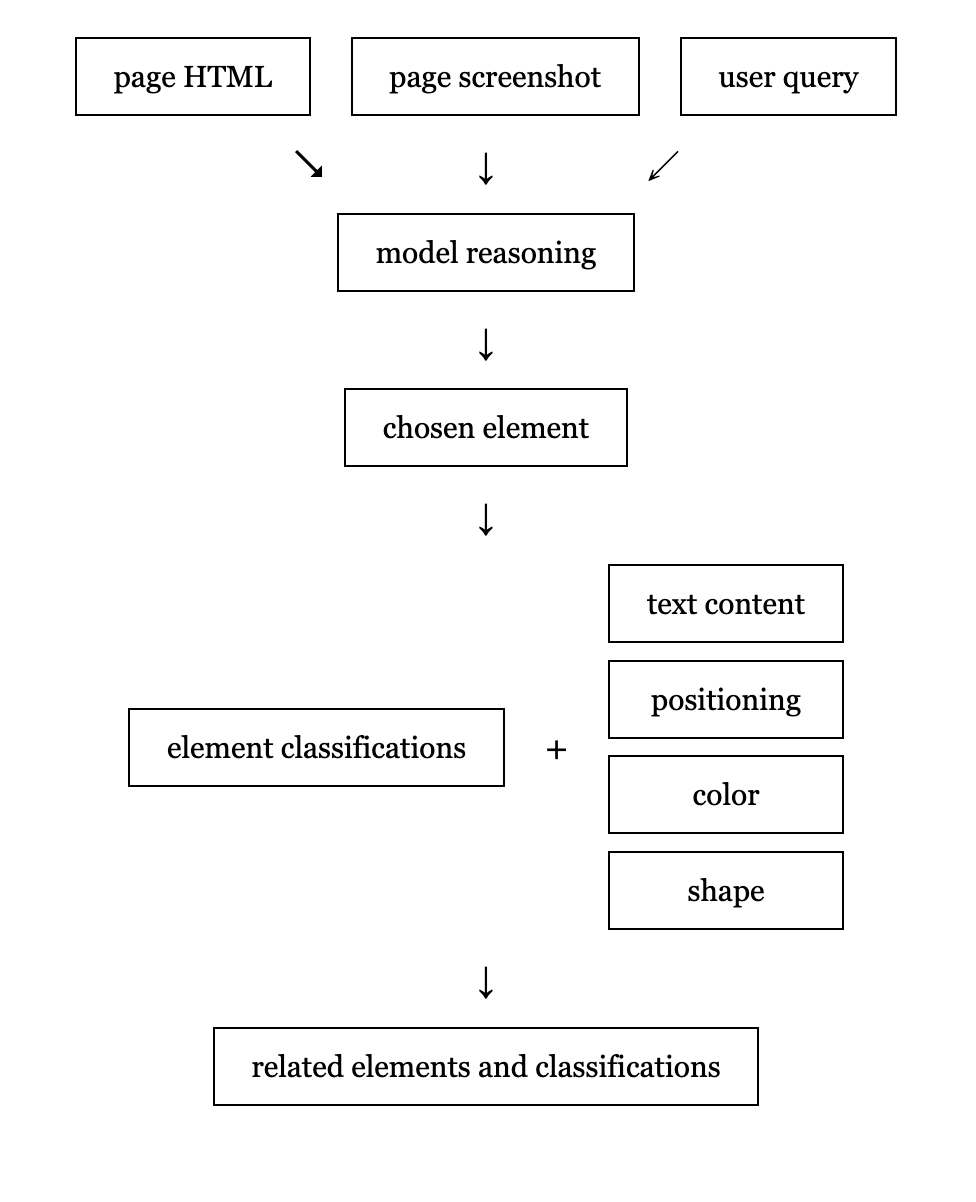
This new approach is a bit of a departure from how we’ve historically validated caches. In effect, we stopped asking "does this look like the element we saw before?" and started asking "does this element still match what the user meant?"
Tying this back to the original button above, if the user specifies “the blue button,” we now strictly enforce that the button is blue.
The result
We’ve now maintained a cache hit rate over 95% while limiting false positives, which allows us to execute steps in 300ms on average, while a completely uncached step takes over 5s due to LLM latency.
In Feb 2026, our attribute-based invalidation flagged 1M potential flakes across 200M resolutions. The new caching allows Momentic to be significantly more reliably than other tools that rely on hardcoded selectors. As a result of these detections, Momentic is able to use AI to adapt and heal the test.
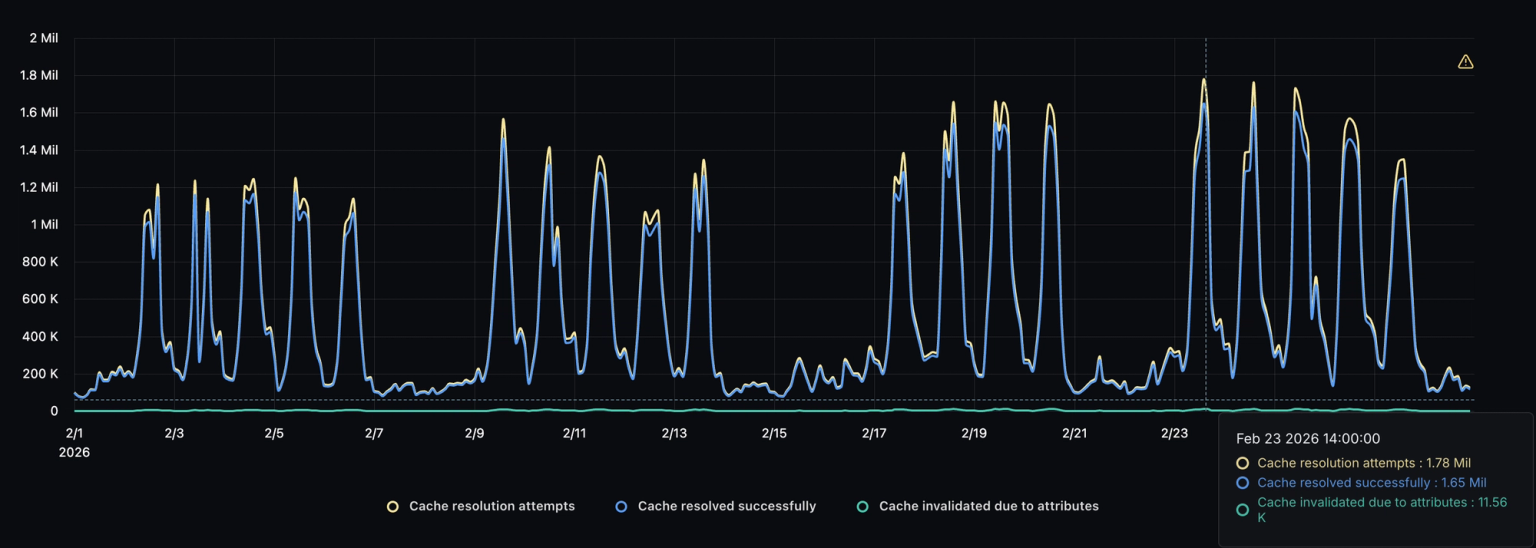
Flaky tests erode trust in the whole platform. Solving them isn't a caching problem, it's an intent problem. That's what we set out to fix with Momentic from the start.
Thanks for reading! Part 2 on the migration from Postgres to Clickhouse is coming soon.
If this kind of problem interests you: connect with us on LinkedIn , X , or check out our open opportunities at momentic.ai .