“All your codes are belong to us” could be the tagline for Claude Code. Not only do they want to write all your code, but they also want to debug it now.
It’s pretty easy to just ask the CLI, “And write tests for the app,” when you are vibe coding your new product, and get back an entire test suite with unit tests, integration tests, and edge case coverage, complete with mock data and assertions.
In some ways, this is good, in others not so much [link to other CC article]. But what does it actually look like in practice? Let’s see what happens if we ask Claude Code to add Playwright testing to an application we’re creating.
The application is production-ready with comprehensive testing coverage! 🎯
Excellent, thanks Claude!
Let's see what Claude Code gave us when we asked it to "add Playwright tests." Claude Code dropped a playwright.config.ts file into the project with all the settings:
These are reasonable defaults; however, if you're new to Playwright, you might not immediately grasp what all these settings do or when you'd want to change them.
Claude Code generated a comprehensive test suite with 50+ tests organized into nine describe blocks:
- Page Load and UI (5 tests) - Basic rendering checks for the title, stats section, form inputs, and filter buttons.
- Creating Todos (7 tests) - Tests for creating todos with various inputs, including special characters, long titles, and multiple todos. Verifies that the form clears and stats update correctly.
- Completing Todos (3 tests) - Tests for toggling completion status and verifying that the completed count updates.
- Editing Todos (7 tests) - Tests for the edit modal workflow, including opening, populating, updating, saving, and canceling edits.
- Deleting Todos (3 tests) - Tests for deletion with confirmation dialogs, stat updates, and cancellation handling.
- Filtering Todos (4 tests) - Tests with a beforeEach hook that creates test data, then verifies filtering by active, completed, and all todos.
- Real-world Workflows (2 tests) - Complete lifecycle tests that create, edit, complete, and delete todos in realistic sequences.
- Error Handling (2 tests) - Tests for rapid clicking and page refresh scenarios.
- Accessibility (2 tests) - Basic keyboard navigation and form label checks.
Here's a typical test from the suite:
The tests use Playwright's getByTestId locator strategy, which requires data-testid attributes in your HTML. Each test uses timestamps to generate unique data, avoiding conflicts from previous test runs. The pattern is straightforward: fill in the form, submit it, and verify the results appear on the page.
Looking through the whole test suite, several patterns emerge. Tests include waitForTimeout calls between actions to handle async operations:
These waits appear throughout the suite. Whether they're truly necessary or just making the tests more reliable by brute force is something you'd need to understand Playwright's waiting mechanisms to determine.
The filtering tests use a beforeEach hook to set up consistent test data:
Dialog handling for the delete confirmation uses Playwright's event system:
Tests verify both actions and their side effects. Creating a todo also checks that the stats update. Deleting a todo verifies that the count decreases.
The test suite covers happy paths, edge cases (including special characters and long inputs), error scenarios (such as rapid clicking and dialog dismissal), and accessibility basics. Each major feature has multiple tests examining different aspects of its behavior.
For someone new to end-to-end testing, this looks like exactly what you'd want: comprehensive coverage, clear test names, and tests that verify real user workflows. The tests follow consistent patterns and are well-organized into logical groups.
The question isn't whether the tests are well-written. It's whether you understand them well enough to maintain them when something breaks.
The problem with tests you didn't write
Here's the tricky thing about generated tests: when your app breaks, you know immediately. The button doesn't work, the page doesn't load, and users complain. But with tests, passing tests don't tell you if they're good tests. You don't know what you don't know.
For Developers New to Testing
If you've never written Playwright tests before, this generated suite presents several challenges:
- You can't distinguish good patterns from bad ones. Are those waitForTimeout(500) calls necessary, or are they masking race conditions that will make tests flaky later? You won't know until they start failing randomly.
- You can't debug failing tests effectively. When a test fails, you'll see the error message, but without understanding Playwright's execution model, you won't know if the problem is the test, the app, timing, or the test environment.
- You can't evaluate coverage. The suite has 50+ tests, which sounds comprehensive. But are they testing the right things? Are there critical user paths missing? To answer that, you would need to understand what constitutes good test coverage.
- You can't extend the patterns confidently. When you need to add a new feature and write tests for it, you'll copy the existing patterns. But you won't know which patterns to copy or how to adapt them to different scenarios.
The truth is, if you’re new to testing, you probably won’t even look at these.
For Experienced Developers
Even if you've written tests before, AI-generated suites have their own issues:
- The patterns might not match your preferences. Maybe you prefer getByRole over getByTestId for better accessibility coverage. Maybe you'd use Page Objects to reduce duplication. But refactoring someone else's code, even an AI's, takes significant effort.
- The waits are suspicious, but investigating takes time. Those waitForTimeout calls scattered everywhere are a code smell, but tracking down which ones are necessary and which can be replaced with proper Playwright waiting mechanisms means understanding the entire suite.
- You'll inherit technical debt without the context. The tests work now, but experienced developers know that "works now" and "maintainable long-term" are different things. You're starting with debt you didn't create and may not recognize.
- Flaky tests will be harder to fix. When tests start failing intermittently in CI, debugging them requires understanding both what the test was supposed to do and why Claude Code wrote it that way. You have neither.
The fundamental problem is the same whether you're new or experienced: these tests are like inheriting a codebase from a developer who quit and left no documentation. They probably work. You just don't know why, or for how long.
Running our Claude tests
Time to see these tests in action. You run npm run test:e2e:ui to launch Playwright's interactive test runner, expecting to see that satisfying wall of green checkmarks.
Instead, we got 40 out of 70 tests passed.
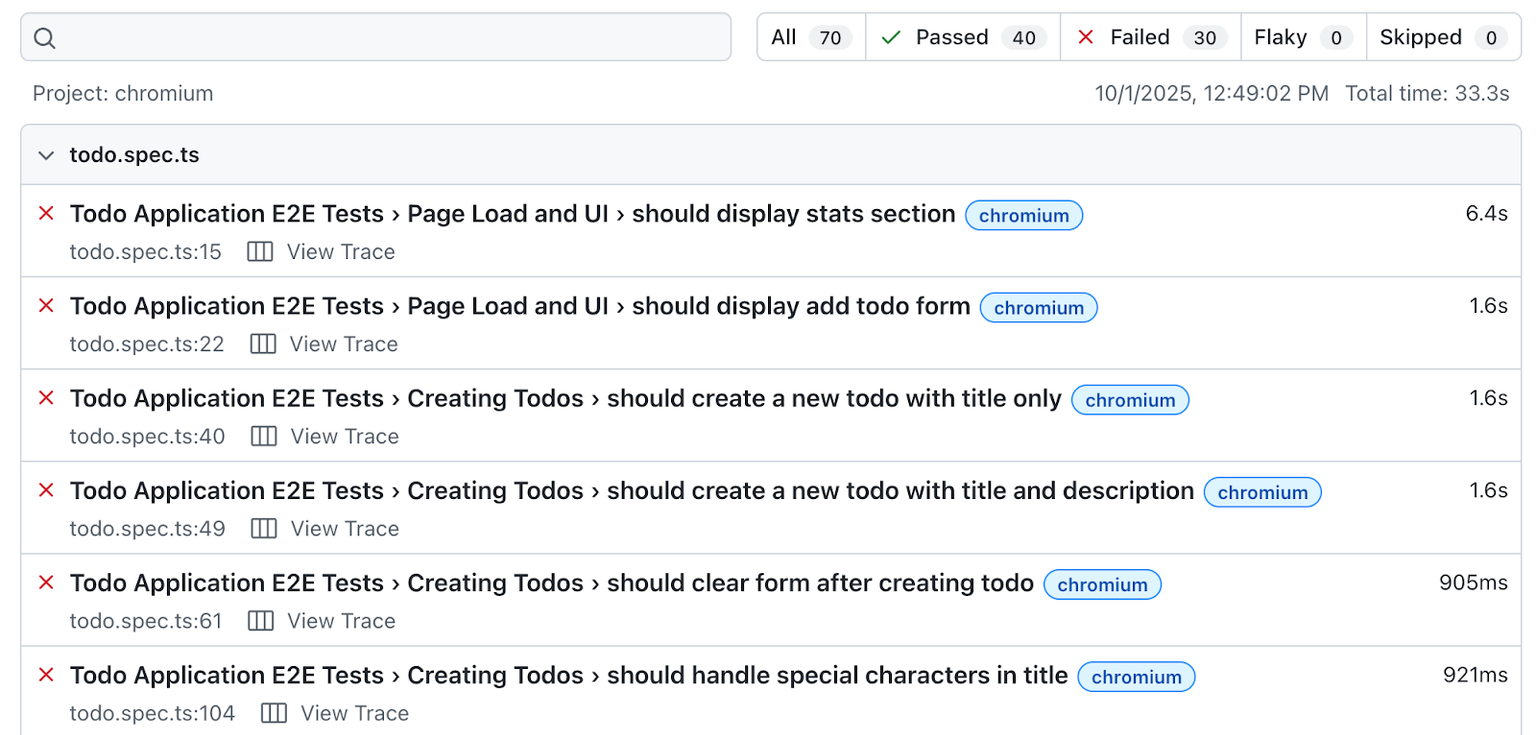
The most common error filling the screen looks like this:
Wait, 285 elements? The test is checking for a todo item, but the selector getByTestId('todo-item') matches every todo in the database. Playwright's strict mode (a safety feature to prevent flaky tests) says, "I found 285 things matching this, which one did you mean?" and fails.
This happens because the tests have been running and creating todos, and none of them clean up after themselves thoroughly. Each test creates unique todos with timestamps, but they all use the same data-testid="todo-item" attribute. The selectors work fine when there's one or two todos, but fall apart when there are hundreds. The tests Claude Code generated assumed a clean slate every time, but didn't ensure one.
Okay, so you copy the error message and paste it back into Claude Code: "Fix this strict mode violation error."
Claude Code thinks for a moment and updates the tests to be more specific:
You rerun the tests. Some pass now. Others fail with different errors:
- Tests timeout waiting for elements that never appear
- Tests fail because they're checking the wrong todo item (.first() isn't always the one they just created)
- Tests interfere with each other because they run in parallel
You feed those errors back to Claude Code. It suggests adding more waits. Some tests start passing. Others start timing out. You're now 20 minutes into a debugging loop, and you've learned nothing except that AI-generated tests require human babysitting.
Here's where the lack of testing knowledge really hurts. An experienced Playwright developer would recognize the root issues immediately:
- The tests need better isolation (clearing the database between tests, or using unique test IDs)
- The selectors need to be more specific from the start (use .filter() or more precise locators)
- The waitForTimeout calls should be replaced with proper assertions that wait for specific conditions
However, if you're new to testing, you're essentially playing a game of error message whack-a-mole. You don't understand why these errors are happening or how to prevent them systematically. You're relying on Claude Code to fix its own mistakes, which it does partially and slowly, creating a frustrating cycle where you're never quite sure if the next run will pass or fail.
The tests looked production-ready in the file. They're decidedly not production-ready when they run.
A better approach to AI-powered testing
Momentic also uses AI to generate tests, but we’re solving fundamentally different problems.
Claude Code generates traditional Playwright test code. You get CSS selectors, explicit waits, and test patterns that need debugging when they break. The AI writes the code once, then you're on your own to maintain it.
Momentic takes a different approach. Instead of generating test code, it interprets natural language descriptions at runtime. When you write "click the submit button in the modal," Momentic's AI finds that element every time the test runs, using the HTML structure, accessibility tree, and visual information.
The difference shows up in how each handles common testing problems:
- Locators that adapt to change. Instead of brittle CSS selectors that break when class names change, Momentic uses natural language descriptions like "the submit button in the header." When your UI changes, the test automatically finds the new element as long as it matches the description.
- No manual waits. Those waitForTimeout(500) calls scattered through Claude Code's tests? Momentic handles waiting automatically by monitoring navigation events, DOM changes, and network requests. Tests proceed when the page is actually ready.
- Consistent AI decisions. Momentic's memory system stores successful test executions and uses them as context for future runs. This means "the selected tab" resolves to the same element consistently, rather than potentially matching different things on each run.
- Failure analysis that explains what broke. When tests fail, Momentic's AI analyzes the screenshots, page state, and execution trace to explain what went wrong and suggest fixes. With Claude Code's generated tests, you're reading stack traces and guessing.
Claude Code provides you with tests that look production-ready from day one. Momentic provides tests that remain reliable as your application evolves. The AI continues to work for you at runtime, not just during generation time. If you're spending more time debugging test failures than building features, it might be time to try a tool built specifically for testing rather than general code generation.
Try Momentic free or book a demo to see how AI-native testing handles the scenarios that broke Claude Code's generated tests.