Maybe you got here through searching “momentic.” If you did, you might have seen a sly “promoted” link on the Google search results:
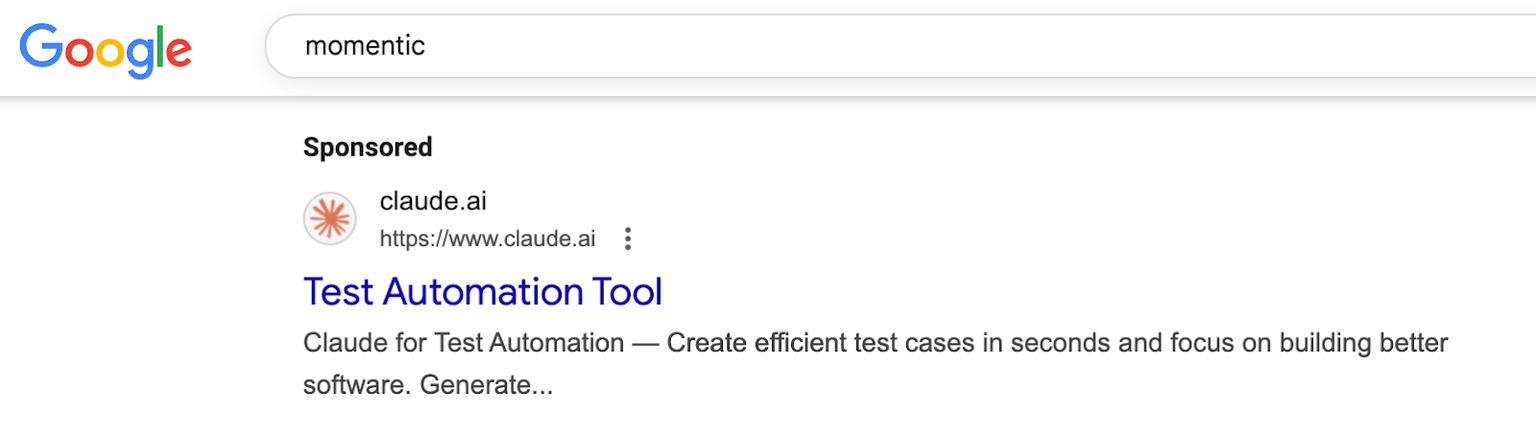
We’re not the only ones. You’ll see something similar if you search for Playwright, and you can check out Anthropic’s other ads to see a few targeting tests.
Claude is great. Truly. We use it, and you use it. But is it a good “test automation tool”?
What’s required from testing
Testing is more than tests.
Tests are just the scripts. The system that runs them, manages them, and extracts value from them is what actually protects your app. We're talking about specific, measurable qualities that separate professional testing from casual validation:
- Determinism means that the same inputs produce the same verdict every time, especially in CI. If your test passes on Monday and fails on Tuesday with no code changes, you can't trust it.
- Stable oracles ensure your assertions reflect business intent. Tests should verify that users can complete their goals, not that a specific div has a particular class name.
- Measurability gives you concrete signals like mutation scores, flake rates, coverage deltas, and mean time to repair on seeded bugs.
- Isolation requires testing environments, seeded data, stubbed networks, and parallel runs.
You want trust in your testing. You want to trust that when your tests pass, your application works (and trust that when they fail, there's a genuine problem). Without this whole system, you just have code that exercises other code, not a testing program that protects your users and your business.
Why code generation tools can't deliver this
Claude Code (or Codex or your favorite flavor of codegen) excel at generating code quickly. If you ask Claude Code to write a test suite for the code you currently have in its context, it will produce tests in a fraction of the time you can, and for everything.
But they fundamentally operate at the wrong layer of abstraction to provide the systematic qualities that real testing demands.
The lack of an oracle
When you prompt Claude to write tests for your code, it examines your current implementation and generates assertions based on what it observes. This creates a circular dependency: your tests now assert that your code does what your code currently does.
Here's a simple example. Say you have a shopping cart with this buggy calculation:
Claude will dutifully generate:
The test passes. The bug ships. Your customers get undercharged sales tax, and your finance team has a bad quarter.
A login form that silently fails but returns a 200 status? Claude will write a test asserting that behavior is correct. A calculation that's off by one? The generated test will expect that wrong value. The AI does not know your actual requirements, only your implementation. It can't distinguish between intentional behavior and bugs.
Non-determinism at every level
Code generation tools introduce variability at multiple points.
The same prompt produces different outputs on every single run. The generated selectors might target different elements depending on the sample HTML you provided. The testing strategies vary based on which examples the model has seen most recently.
This variability compounds in CI. Your test suite becomes non-reproducible. A failing test might pass when regenerated, not because the bug was fixed, but because the AI generated a slightly different test. You lose the ability to bisect failures or maintain consistent baselines.
No infrastructure management
Code generation stops at the test file. It doesn't provision test environments, manage test data, configure network stubs, or handle authentication. It can't coordinate parallel execution, implement smart retries, or manage test dependencies.
When Claude generates a Playwright test, it might include a page.goto('http://localhost:3000'). But what’s running on that local server? What data is in the database? What external services are being called? The generated code assumes an environment that doesn't exist in CI.
Missing metrics and observability
AI assistants generate code, not metrics. They don't track flake rates, measure execution times, or compute mutation scores. They can't tell you which tests are becoming less reliable over time or which parts of your codebase have inadequate coverage.
Without these signals, you're running blind. You have tests, but you don't know if they're effective. You can't make informed decisions about where to invest testing effort or when to refactor problematic test areas.
Zero Maintenance
Generated tests create technical debt from day one. The AI doesn't understand your team's conventions, your abstraction patterns, or your workflows. It generates inline selectors instead of page objects. It hardcodes values that should be configurable. It doesn't create reusable fixtures or helper functions.
When your UI changes, you can't just update a single selector in a shared component. You need to regenerate or manually fix dozens of tests. When business logic evolves, you can't just update the oracle definition. You need to prompt the AI again and hope it understands the new requirements.
AI testing wrapped in trust
The solution isn't to abandon AI in testing. AI is an excellent option for removing the manual, tedious part of testing–writing tests. You can use AI for what it's good at (understanding intent, generating variations, finding edge cases), but you must wrap it in the infrastructure that makes testing actually work.
Purpose-built AI testing systems like Momentic still use AI, but they build comprehensive systems around it to deliver reliability at scale.
Natural language with deterministic execution
Momentic allows you to write tests in natural language, but the execution is deterministic. When you write "click the submit button in the user dialog," Momentic's AI agents convert this to reliable browser actions. The system uses specialized agents for different tasks: locator agents find elements, assertion agents verify state, and extraction agents pull data from pages. Each agent can be versioned and configured, giving you control over how AI interprets your tests.
The natural language descriptions become stable contracts. If your UI changes but the intent remains the same, Auto-healing automatically adapts. The "submit button" might move or change appearance, but as long as it's still recognizably a submit button, your test keeps working.
Memory and consistency
To eliminate flakiness from varying AI interpretations, Momentic stores successful AI completions and uses them as context for future runs. When the AI encounters "the selected tab," it remembers whether that meant "the currently selected tab" or "the tab labeled 'Selected'" from previous successful runs. This memory system ensures consistent decisions across test executions.
Memory traces are securely isolated per organization, automatically expire after 30 days of inactivity, and only include the most relevant patterns to prevent unbounded growth.
Infrastructure as code
Momentic provides the testing infrastructure that code generation tools lack. Modules allow you to create reusable test components with parameters, turning common workflows like authentication into building blocks. These modules can be cached to skip redundant execution, with authentication state (cookies, localStorage, IndexedDB) automatically saved and restored between runs.
Variables flow through tests naturally using the env object, with both global and persistent variables for suite-level coordination. Smart waiting handles timing automatically, checking for navigation events, DOM changes, and network requests before proceeding.
Failure recovery and analysis
When tests fail, Momentic doesn't just report an error. The failure recovery system (currently in beta) can diagnose transient issues like slow page loads or unexpected modals and automatically generate recovery steps. If a marketing pop-up appears unexpectedly, Momentic will close it and retry the original action.
For non-recoverable failures, Momentic provides AI-powered root cause analysis. It examines screenshots, page state, and execution history to explain what went wrong and suggest fixes. This analysis is presented in both the web UI and CLI output, converting cryptic failures into actionable insights.
Test quality management
Momentic's quarantine system prevents flaky tests from breaking CI while you fix them. Tests can be automatically quarantined based on configurable rules (pass rate, failure count, flake rate) with filters for specific repositories, branches, or test labels. Quarantined tests still run, but don't affect pipeline status.
For network-dependent tests, Momentic provides request mocking to intercept and modify API responses. You can return fake data, modify feature flags, or test error states without changing your backend. Mocks are versioned and can fetch real responses before modifying them.
From test scripts to testing systems
Claude Code is fantastic for what it does: generating test code quickly, suggesting edge cases, and translating requirements into assertions. But it operates in isolation. It can't remember what "the submit button" meant in yesterday's run. It can't cache authentication sessions. It can't quarantine flaky tests or analyze failures with screenshots. It can't automatically recover from transient issues or coordinate parallel test execution across suites. It writes code, but code is just the beginning of testing.
Full AI testing frameworks build around AI to create the infrastructure for testing. Each piece reinforces the others. Memory improves consistency. Consistency enables caching. Caching speeds up execution. Faster execution allows more comprehensive testing. Better coverage catches more bugs. Catching bugs builds trust.
The result is AI that accelerates test creation without sacrificing reliability. You write tests in natural language, but they execute with the determinism of traditional automation. The AI handles element finding and assertion evaluation, while the infrastructure ensures those operations are repeatable, measurable, and maintainable.
This is why "AI testing" isn't about choosing between human and machine. It's about building systems where AI and infrastructure work together to deliver something neither could achieve alone: comprehensive, maintainable, trustworthy test coverage that adapts to change without breaking.